
八爪鱼采集器官方免费版 v8.2.4
软件大小:74.2MB
软件语言:简体中文
用户评分:
软件类型:国产软件
授权方式:免费软件
软件官网:
更新时间:2020/12/27
软件分类:系统优化
运行环境:
平台检测 无插件 360通过 腾讯通过 金山通过 瑞星通过
普通下载
通过人工搜索网站或者网页信息获取大量的数据,他的成本无疑是巨大的,如今的人工费用早已不是曾经的廉价年代,因此如何更高效更廉价的获取规范化的数据成了一个必须攻克的难题,八爪鱼采集器官方免费版是由深圳视界信息技术有限公司官方打造的一款网页采集器,通过该公司自主研发的分布式云计算平台,可在不同的网站或网页轻松的获取重要数据信息,而且速度极快,只需一瞬间获取的数据量更是以人工获取数据途径的数十倍。该软件简化了采集工作,改变了传统获取信息的方式,逐渐摆脱对人工的依赖,在他的运作下,用户可以精准的获取任何页面需要的数据,且数据十分规整,如此事半功倍的采集软件,用户们还不赶紧将八爪鱼采集器官方免费版下载进行体验,也许你在该软件的帮助下,工作效率就成了公司第一名呢!
2、各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3、监控竞争对手最新信息,包括商品价格及库存;
4、监控各大社交网站,博客,自动抓取企业产品的相关评论;
5、收集最新最全的职场招聘信息;
6、监控各大地产相关网站,采集新房二手房最新行情;
7、采集各大汽车网站具体的新车二手车信息;
8、发现和收集潜在客户信息;
9、采集行业网站的产品目录及产品信息;
10、八爪鱼采集器在各大电商平台之间同步商品信息,做到在一个平台发布,其他平台自动更新。
适合产品、运营、销售、数据分析、政府机关、电商从业者、学术研究等多种身份职业
2、舆情监控
全方位监测公开信息,抢先获取舆论趋势
3、市场分析
获取用户真实行为数据,全面把握顾客真实需求
4、产品研发
强力支撑用户调研,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
简易采集模式内置上百种主流网站数据源,如京东、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
2、智能采集
该软件可根据不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
3、云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提升采集效率,保障数据时效性。
4、API接口
通过API,可以轻松获取该软件任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强大的API体系,还可以无缝对接公司内部各类管理平台,实现各类业务自动化。
5、自定义采集
针对不同用户的采集需求,该软件可提供自动生成爬虫的自定义模式,可准确批量识别各种网页元素,还有翻页、下拉、ajax、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某一天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据需要对选择时间进行多重组合,灵活调配自己的采集任务。
7、全自动数据格式化
该软件内置了强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集过程中全自动处理,无需人工干预,即可得到所需格式数据。
8、多层级采集
很多主流新闻、电商类的网站,里面包含一级商品列表页,也包含二级商品详情页,还有三级评论详情页面;不论网站有多少层级,该软件都可以不限制层级的采集数据,满足各类业务采集需求。
9、支持网站登录后采集
八爪鱼采集器内置了采集登录模块,只需配置目标网站的账号密码,即可用该模块采集到登录后的数据;同时还具备采集Cookie自定义功能,首次登录以后,可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站的采集。
操作简单,完全可视化图形操作,无需专业IT人员,任何会使用电脑上网的人都可以轻松掌握。
2、云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,可以很短的时间内 获取成千上万条信息。
3、拖拽式采集流程
模拟人的操作思维模式,可以登陆,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4、图文识别
内置可扩展的OCR接口,支持解析图片中的文字,可将图片上的文字提取出来。
5、定时自动采集
采集任务自动运行,可以按照指定的周期自动采集,并且还支持最快一分钟一次的实时采集。
6、2分钟快速入门
内置从入门到精通所需要的视频教程,2分钟就能上手使用,另外还有文档,论坛,qq群等。
7、免费使用
它是免费的,并且免费版本没有任何功能限制,你现在就可以试一试,立即下载安装。

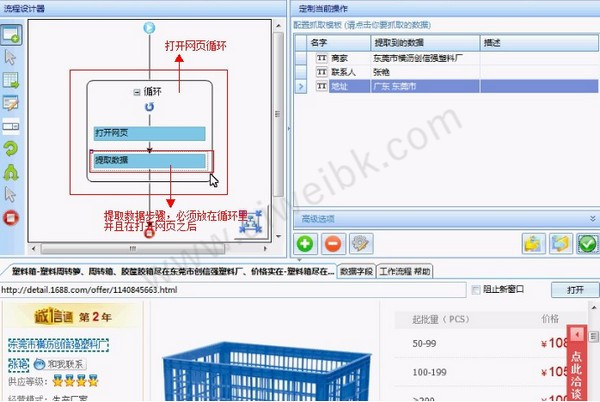
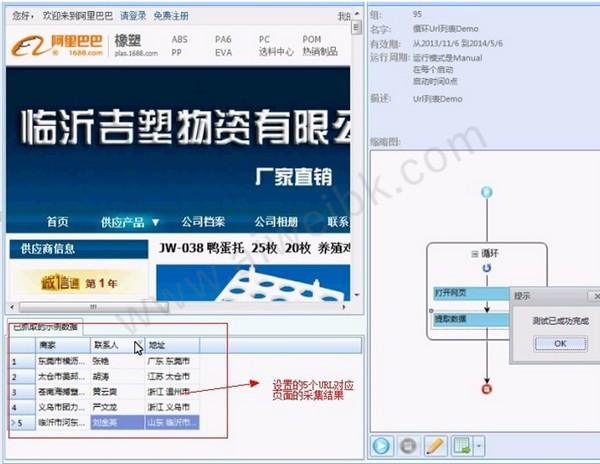
2、接下来往循环中拖入一个打开网页的步骤-->选中打开网页步骤-->勾选上使用当前循环里的URL作为导航地址-->点击保存。系统会在界面下方的浏览器中打开循环中选中的URL对应的网页

3、到这里,循环打开网页的流程就配置完成了,运行流程的时候,系统会逐个的打开循环中设置的URL。最后我们不需要配置一个采集数据的步骤,这里就不在多讲,大家可以参考从入门到精通系列1:采集单个网页 这篇文章。下图就是最终和流程
4、下面是流程最终的运行结果
迭代功能
更新了新增字段、修改字段、格式化数据的交互方式,将数据操作集中在数据预览区域
针对不同类型的字段,区分操作项,点击可展开不同的菜单项
优化了配置XPath的操作,即时显示XPath在页面中的识别结果
Bug修复
修复自定义下拉框类型网页无法正常获取问题
修复同名的自定义任务无法正常保存问题
修复对修改去重数据配置后应用未保存直接采集出现的报错问题
修复部分采集产生错误报告无法正常采集数据问题
修复网址栏修改网址出现丢失其他步骤相关场景问题
功能特色
1、金融数据,如季报,年报,财务报告, 包括每日最新净值自动采集;2、各大新闻门户网站实时监控,自动更新及上传最新发布的新闻;
3、监控竞争对手最新信息,包括商品价格及库存;
4、监控各大社交网站,博客,自动抓取企业产品的相关评论;
5、收集最新最全的职场招聘信息;
6、监控各大地产相关网站,采集新房二手房最新行情;
7、采集各大汽车网站具体的新车二手车信息;
8、发现和收集潜在客户信息;
9、采集行业网站的产品目录及产品信息;
10、八爪鱼采集器在各大电商平台之间同步商品信息,做到在一个平台发布,其他平台自动更新。
软件亮点
1、满足多种业务场景适合产品、运营、销售、数据分析、政府机关、电商从业者、学术研究等多种身份职业
2、舆情监控
全方位监测公开信息,抢先获取舆论趋势
3、市场分析
获取用户真实行为数据,全面把握顾客真实需求
4、产品研发
强力支撑用户调研,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍
1、简易采集简易采集模式内置上百种主流网站数据源,如京东、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
2、智能采集
该软件可根据不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
3、云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提升采集效率,保障数据时效性。
4、API接口
通过API,可以轻松获取该软件任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强大的API体系,还可以无缝对接公司内部各类管理平台,实现各类业务自动化。
5、自定义采集
针对不同用户的采集需求,该软件可提供自动生成爬虫的自定义模式,可准确批量识别各种网页元素,还有翻页、下拉、ajax、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某一天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据需要对选择时间进行多重组合,灵活调配自己的采集任务。
7、全自动数据格式化
该软件内置了强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集过程中全自动处理,无需人工干预,即可得到所需格式数据。
8、多层级采集
很多主流新闻、电商类的网站,里面包含一级商品列表页,也包含二级商品详情页,还有三级评论详情页面;不论网站有多少层级,该软件都可以不限制层级的采集数据,满足各类业务采集需求。
9、支持网站登录后采集
八爪鱼采集器内置了采集登录模块,只需配置目标网站的账号密码,即可用该模块采集到登录后的数据;同时还具备采集Cookie自定义功能,首次登录以后,可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站的采集。
软件优势
1、操作简单操作简单,完全可视化图形操作,无需专业IT人员,任何会使用电脑上网的人都可以轻松掌握。
2、云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,可以很短的时间内 获取成千上万条信息。
3、拖拽式采集流程
模拟人的操作思维模式,可以登陆,输入数据,点击链接,按钮等,还能对不同情况采取不同的采集流程。
4、图文识别
内置可扩展的OCR接口,支持解析图片中的文字,可将图片上的文字提取出来。
5、定时自动采集
采集任务自动运行,可以按照指定的周期自动采集,并且还支持最快一分钟一次的实时采集。
6、2分钟快速入门
内置从入门到精通所需要的视频教程,2分钟就能上手使用,另外还有文档,论坛,qq群等。
7、免费使用
它是免费的,并且免费版本没有任何功能限制,你现在就可以试一试,立即下载安装。

八爪鱼采集器教程
1、先我们新建一个任务-->进入流程设计页面-->添加一个循环步骤到流程中-->选中循环步骤-->勾选上软件右方的URL 列表勾选框-->打开URL列表文本框-->将准备好的URL列表填写到文本框中2、接下来往循环中拖入一个打开网页的步骤-->选中打开网页步骤-->勾选上使用当前循环里的URL作为导航地址-->点击保存。系统会在界面下方的浏览器中打开循环中选中的URL对应的网页
3、到这里,循环打开网页的流程就配置完成了,运行流程的时候,系统会逐个的打开循环中设置的URL。最后我们不需要配置一个采集数据的步骤,这里就不在多讲,大家可以参考从入门到精通系列1:采集单个网页 这篇文章。下图就是最终和流程
4、下面是流程最终的运行结果
更新日志
v8.2.4迭代功能
更新了新增字段、修改字段、格式化数据的交互方式,将数据操作集中在数据预览区域
针对不同类型的字段,区分操作项,点击可展开不同的菜单项
优化了配置XPath的操作,即时显示XPath在页面中的识别结果
Bug修复
修复自定义下拉框类型网页无法正常获取问题
修复同名的自定义任务无法正常保存问题
修复对修改去重数据配置后应用未保存直接采集出现的报错问题
修复部分采集产生错误报告无法正常采集数据问题
修复网址栏修改网址出现丢失其他步骤相关场景问题
猜你喜欢








相关推荐










- 软件周排行
- 软件总排行
- 01

framedyn.dll2021-10-19
- 02

mscorlib.dll2021-10-18
- 03

steam.dll2021-09-21
- 04

winstepnexus19.2破解版2021-09-15
- 05

qt5core.dllwin102021-09-12
- 06

mfc100u.dll文件64位2021-08-29
- 07

mfc100.dll64位2021-08-27
- 08

d3dx9_24.dllwin1064位2021-08-20
- 09

d3dx9_37.dll64位2021-08-19
- 10

d3dx9_39.dll官方版2021-08-18
- 11

msvcr110.dll文件64位2021-08-15

























