fakeapp2.2汉化破解版
软件大小:1.42GB
软件语言:简体中文
用户评分:
软件类型:国产软件
授权方式:免费软件
软件官网:
更新时间:2021/08/12
软件分类:视频处理
运行环境:
平台检测 无插件 360通过 腾讯通过 金山通过 瑞星通过
普通下载
相关软件
- Vidmore Video Enhancer(视频增强器)最新破解版 v1.0.12
- Ashampoo Movie Studio Pro v3.3.0中文破解版
- Vidmore Video Converter中文破解版 v1.3.10
- ACDSee亮鱼剪辑破解版
- HitFilm Express 18中文破解版 v18.0.12006.43385
- Apeaksoft Video Converter Ultimate(视频转换工具)中文破解版 v2.0.10
- Franzis CutOut 10 pro中文破解版
- Pixologic ZBrush v2022.0中文破解版
- CorelDRAW 2022中文破解版 v24.1.0.389
- Adobe Premiere Pro2022绿色精简版 v22.0.0.169
FakeApp是一个先进的视频编辑应用程序,使用户能够利用机器学习和人工智能处理的功能改变视频中人的脸。这款软件利用所谓的 "深度模拟 "算法发展的所有最新进展,代表了一个多合一的软件包,使任何人都能成功地将视频中的人脸替换成一个完全不同的人的脸。虽然这种类型的应用程序最初只能在人脸周围添加计算机生成的或静态的二维图像(假眼镜、兔子耳朵、胡子和其他简单的元素),但这一领域令人难以置信的进步使现代软件开发人员能够训练应用程序,将大型数据库中的面部图像变形和适合视频中的目标脸。最初是用于喜剧节目的和电视广告或电影的大型预测的专业换脸,最近,各种能够换脸的软件解决方案也被广泛用于所有领域。虽然这个应用程序可以创造出真实的换脸结果,但要做到这一点,用户必须投入相当多的时间、精力,并提供足够的参考数据。这种参考数据必须以大量面部照片的形式出现,这些照片将被分析并准备用于匹配和变形到所有可能的位置。为了简化参考图像的收集过程,用户可以使用这个应用程序加载具有必要的面部数据的特定训练视频。收集的数据越多,最后的结果就越好。为了成功地改变某人的脸,Fake App会首先分析你给它的视频,并试图不仅分离出所有的面部表情,而且还分离出眼睛、嘴巴和其他面部结构的位置和动作。收集到这些数据后,该应用程序将尝试将你的参考照片与视频相匹配,仔细尝试保留眼睛和嘴部运动等元素。最终的结果不仅高度依赖于参考照片的范围和质量,而且还依赖于该应用程序用于正确匹配所有东西的时间。我们在下文中提供了关于fakeapp2.2汉化破解版的详细安装教程和使用教程,感兴趣的朋友下载试试吧。
需要CUDA、CuDnn、VS2015,
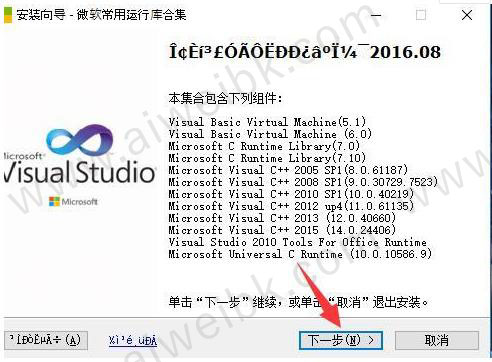
2、全面两个软件安装简单,请自行下载安装,这里我们从安装VS2015开始,安装vs2015的过程很慢,数据包本身也很大,运行软件后点击“下一步”
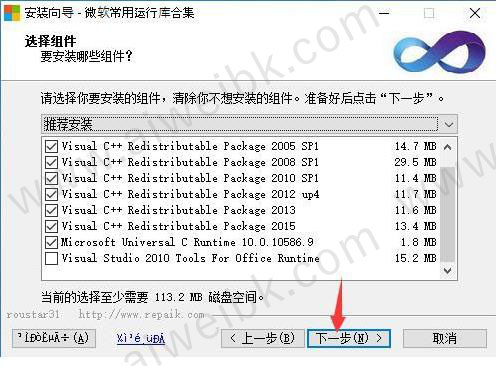
3、安装运行库其实也很简单,一切使用默认选项,一直点击“下一步即可”
4、安装按成,点击“完成”即可
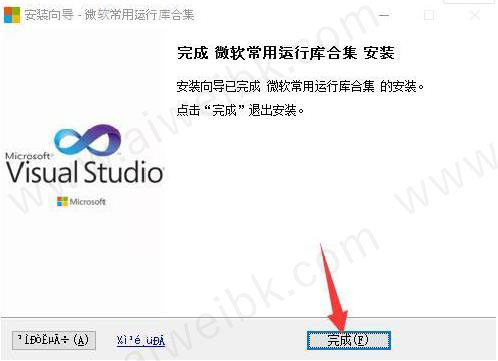
5、安装完成后可以通过【控制面板】->【程序】->【程序和功能】进行查看,这里会出现很多Visual C++ 开头的文件。

6、接下来安装fakeapp
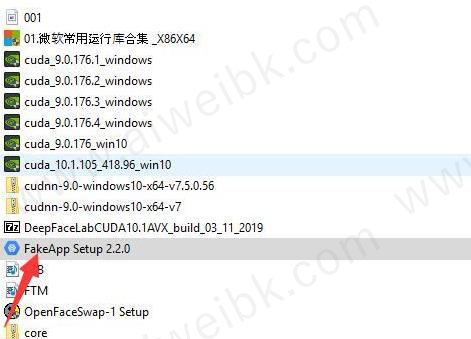
7、系统会跳出安全警告,可以直接点Run继续。
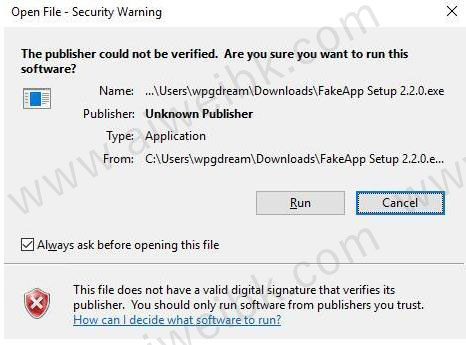
8、当桌面出现图标时表示安装成功
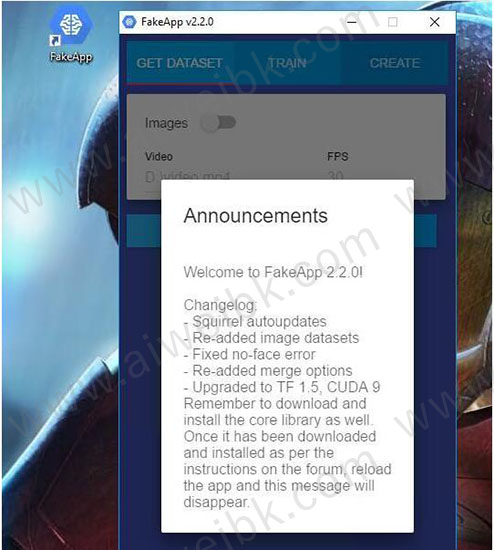
9、接下来需要更新软件日志,下载和安装内核
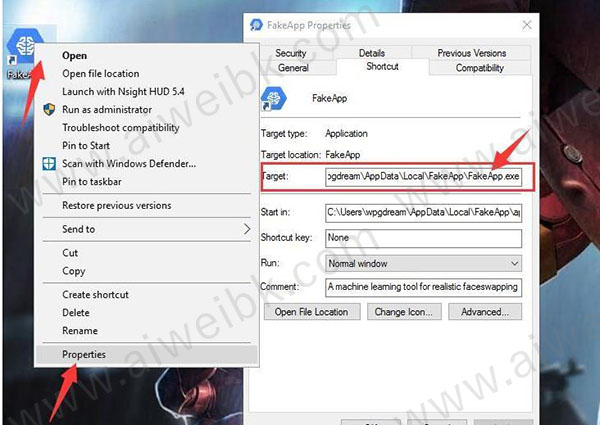
10、通过右键桌面图标——属性(Properties)——快捷方式(Shortcut)——目标路径(Target )找到Fakeapp的真是安装路径。
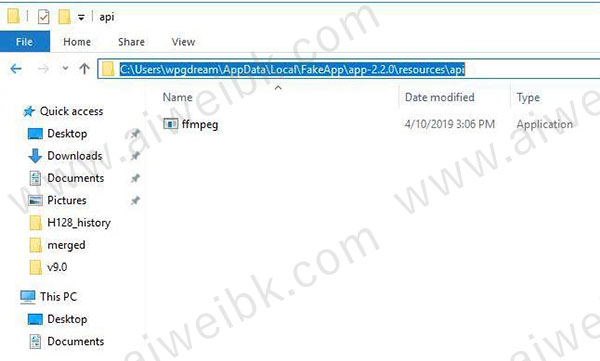
找到….\api 文件夹,一般情况下载里面只有一个ffmpeg文件。
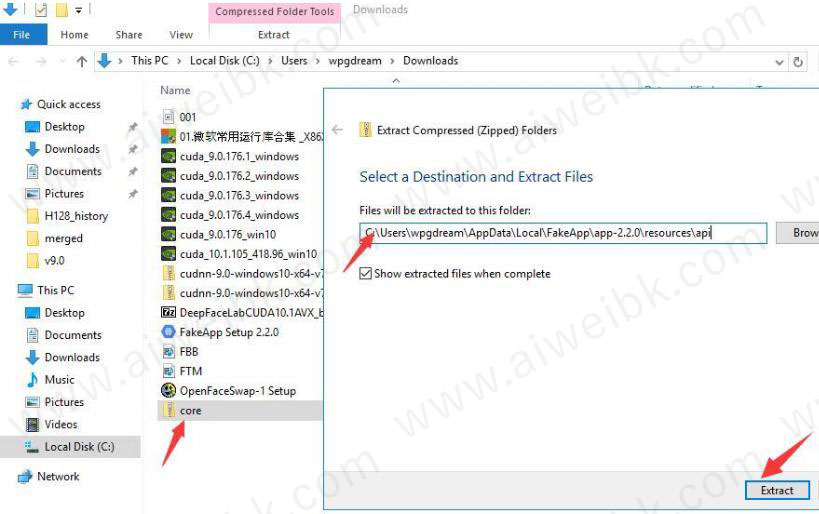
11、先复制上面的路径,然后右键单击core压缩包,在跳出的窗口里黏贴路径,点击解压(Extract)。
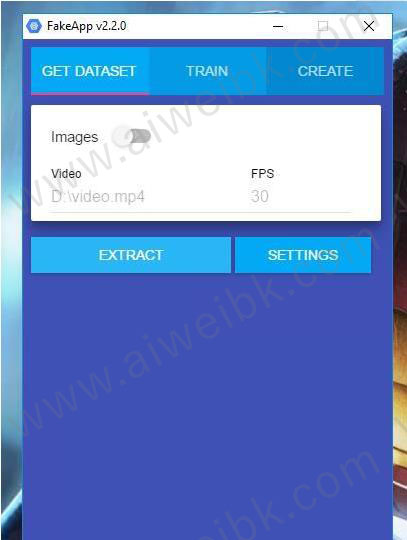
12、解压完成后,再次打开桌面上的Fakeapp,就正常进入软件了。
获取脸部图片、训练模型、生成视频
在开始之前你需要先准备两个视频,一个是A视频,一个是B视频,换脸软件可以把B的脸换到A上面。这里加上A视频是FBB(范冰冰),B视频是FTM。这两个视频放在一个叫workspace的目录里面。下面的路径都为相对G:\FakeApp\workspace\的路径,路径并没有特殊要求,你可以更具自己的情况来选择。
一、获取脸部图片
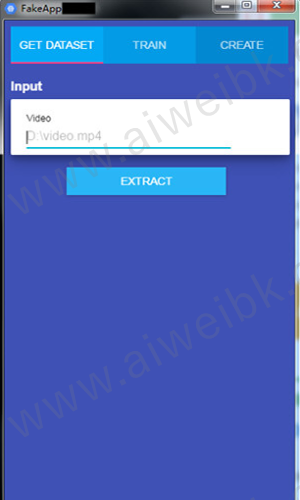
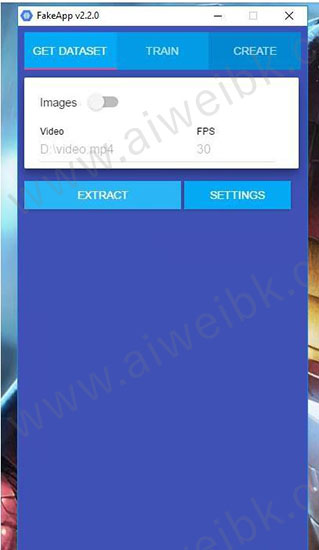
1、选中GET DATESET 出现如下界面。
2、这一步的目的是讲视频分割成图片,然后从图片中提取脸部。
这个环节只需要填写两个地方,一个是Vidoe视频路径,一个是帧率FPS,默认为30.
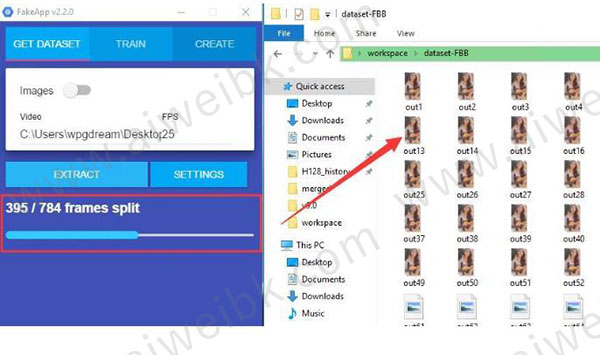
3、因为我们有两个视频,所以需要分两次次来。.
先在Video中输入G:\FakeApp\workspace\FBB.mp4 ,这个路径不一定是这个样子要更具你的实际情况来。 帧率可以通过视频文件右键属性进行查看,一般是30,24之类。
输入完成后点击EXTRACT(提取) 开始提取。
4、提取分两个阶段,一个是把视频分割成图片,如上图。 一个是把图片中的人脸提取出来保存成新的图片,如下图。
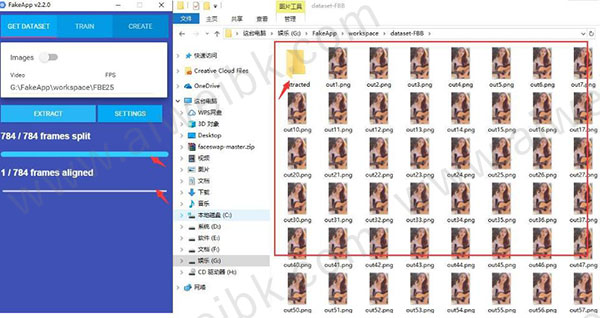
5、等待进度条结束后跳出Traning dataset successfully 这个提示窗口就证明成功了。点击OK关闭提示窗口。
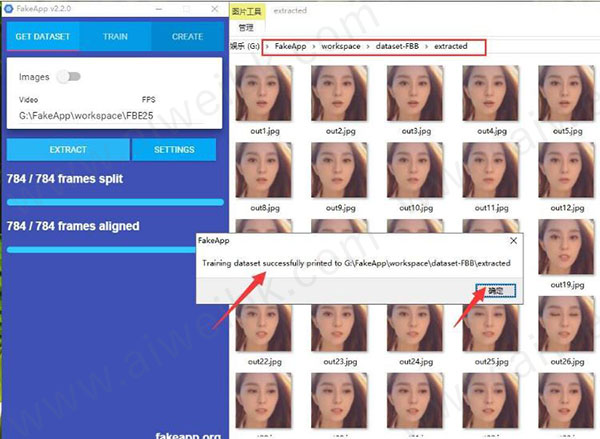
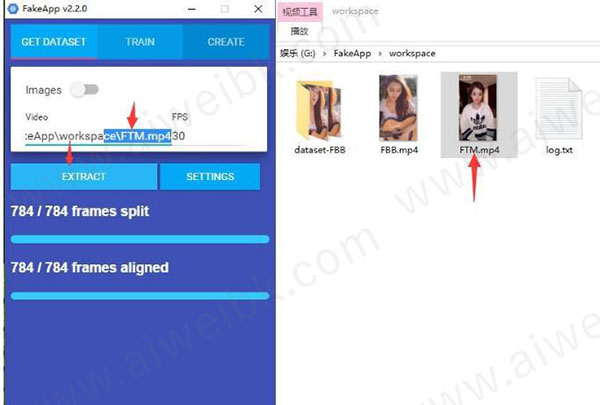
6、用同样的方式操作FTM.mp4
Video中输入G:\FakeApp\workspace\FTM.mp4 ,这个路径不一定是这个样子要更具你的实际情况来。同样需要输入帧率。
这两个过程完全是一样的,截图如下,就不多解释了。
二、训练模型
1、模型是很重要的一个东西,也是一个极其消耗时间的东西。训练模型对配置的要求也是比较高。
训练界面主要是上个输入框
Model : 模型的保存路径 (….\workspace\Model)
Data A: 被换的人脸(….\workspace\dataset_FBB\extracted)
Date B: 拿去换的人脸(…..workspace\dataset_FTM\extracted)
“….”代表你自己的路径。
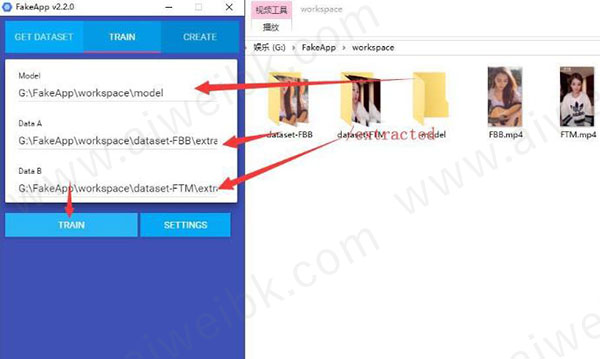
2、输入路径之后,点击TRAIN开始训练。稍等片刻下面就会显示Loss A:xxxx ,LossB:xxxx 。 同时Model 目录下除了四个文件。同时还会跳出一个有很多脸的预览窗口。
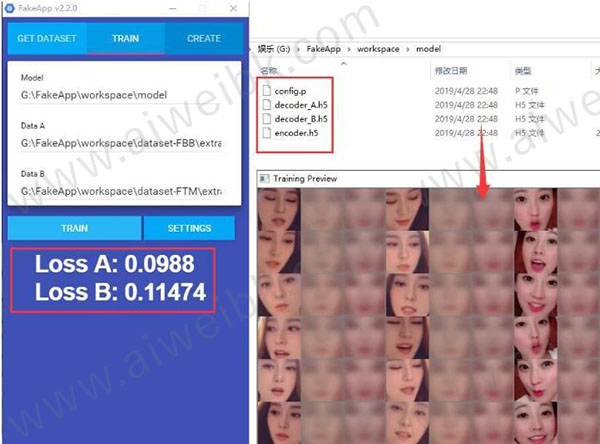
3、这一个环节是非常耗时间的,一般需要几天时间。软件不会自动停止,你不想训练模型的时候可以手动关闭。下次开启会继续训练。 手动关闭的方法为,鼠标移动到预览窗口,然后按Q结束。
判断这个阶段是否完成了,可以通过两个指标去看。
①Loss A,Loss B 数字越来越像,小到了0.02左右,就差不多了
②人脸预览图越来越清晰,第二列第三列和第一列一样清晰,就证明差不多了。
训练结束后,即可开始生成视频。
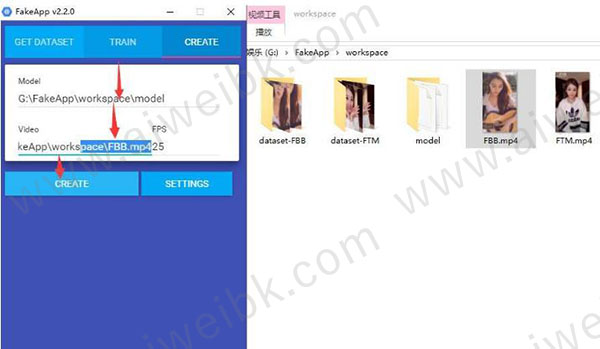
4、生成视频的过程也是细分了好几个步骤。
首先,你需要输入Model 路径(…\workspace\Model )。Video路径(…\workspace\FTM.mp4) FPS(30)
然后,点击Create。
然后程序自动开始,处理过程可分成4个阶段。
①、生成图片
②、截取脸部
③、合成图片
④、合成视频
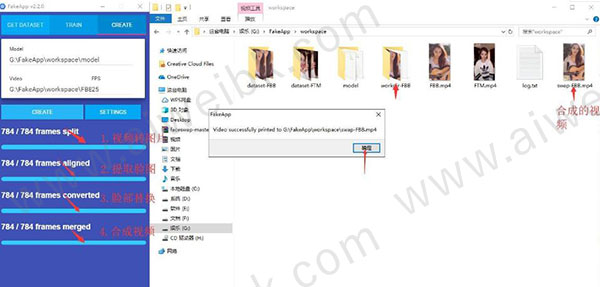
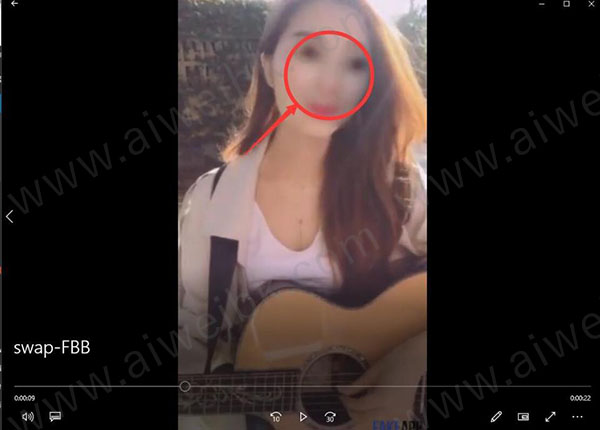
5、上面四个步骤是软件自动运行,运行结束之后就可以看到一个叫swap-FTM的视频了。这就是换脸后的视频。
因为我训练时间非常短,所以这个脸是非常模糊的,几乎看不起是谁。如果你训练的时间够长,这里就会非常清晰了。
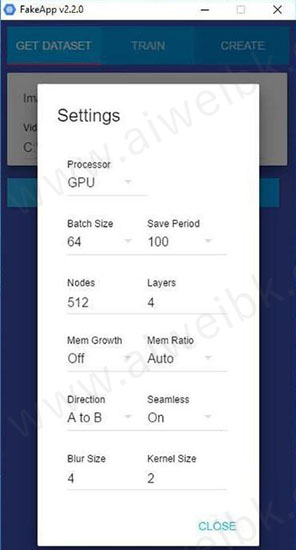
这个选项用来指定运行环境,是选着GPU还是CPU。 一般来说如果你有显卡肯定选GPU,如果没有就选CPU,GPU的速度比CPU快几十倍的样子。
2、Batch Size:批量大小
这是一个深度学习中的专有名词,在训练的模型的时候并不是一次训练所有图片,而是分批进行训练。原则上来说越大越好(2的指数),但是数字越大消耗的显存越到,需要的配置越高。
3、Save Period: 保存间隔
默认为100,你可以根据自己的需要修改。
4、Nodes: 神经节点数
一般不修改,越大能力越强,需要配置越高。 如果你的电脑配置较低,可以适当降低这个值,比如改为256
5、Layer: 神经网络层数
一般不修改,越大能力越强,需要配置越高。
6、Mem Growth:内存增长
从理解上来说是,内存是否自动增长。
7、Men Ratio: 使用内存量 0.1/0.2/0.3
控制使用显存的大小。默认为自动,如果调整可能会出错。
8、Driection: A to B 转换方向
一般默认,也可以修改成B to A ,意思就是把B变成A。
9、Blur Size : 模糊的大小
融合的时候边缘模糊参数,如果感觉边缘比较生硬,可以适当增大这个参数。
2、TRAIN:训练模型,根据第一步中生成的数据集,机器会自动地帮你训练模型,从而进行面部的替换。
3、CREATE:生成视频,这一步便是整个实验中最为神奇的地方,他能根据你训练出的模型,将给定视频素材中人物的面部进行替换,最后生成替换后的视频。
常见问题
如何把A视频的脸,替换进B视频 ?
1、收集A,B的脸
因为是视频,所以要用一些特殊的技巧,把一个视频,转换成一张张图片,比如10s的视频,可能会有上百张图片,然后在上百张图片里,找出带有人脸的,最终都截取成相同大小的,比如256*256的脸图片
2、训练模型,A->B
有了A的256*256脸,和B的256*256脸,通过一些特殊的技巧,能找到两张脸之间联系,图片数越多,联系也就越紧,找到关系后,保存成 模型。这个模型的作用就是,给一张A的脸,输入进模型,模型会给出B的脸
3、换脸
随便找一个A的视频,依旧是转换成一张张图片,依旧要找出带有人脸的图片。把这一张张图片,丢进第2步得到的模型,就能得出一张张替换成B脸的图片。最后把所有的图片,再合并成视频,换脸完成。
作业系统及CPU: 64Bit位
内存: 8G或以上
显卡:(CUDA)NVIDIA整合技术官方文档
CUDA Toolkit 8.0或CUDA Toolkit 9.1
2、辅助软件
JAVA程序 下载GO!…
Redistributable for Visual Studio 2015 下载位置
FFmpeg 下载GO!…
Light Image Resizer
Avidemux
fakeapp安装教程
1、下面先来介绍安装部分,因为这是一个基于深度学习的软件,所以需要装很多和深度学习相关的依赖软件。需要CUDA、CuDnn、VS2015,
2、全面两个软件安装简单,请自行下载安装,这里我们从安装VS2015开始,安装vs2015的过程很慢,数据包本身也很大,运行软件后点击“下一步”
3、安装运行库其实也很简单,一切使用默认选项,一直点击“下一步即可”
4、安装按成,点击“完成”即可
5、安装完成后可以通过【控制面板】->【程序】->【程序和功能】进行查看,这里会出现很多Visual C++ 开头的文件。
6、接下来安装fakeapp
7、系统会跳出安全警告,可以直接点Run继续。
8、当桌面出现图标时表示安装成功
9、接下来需要更新软件日志,下载和安装内核
10、通过右键桌面图标——属性(Properties)——快捷方式(Shortcut)——目标路径(Target )找到Fakeapp的真是安装路径。
找到….\api 文件夹,一般情况下载里面只有一个ffmpeg文件。
11、先复制上面的路径,然后右键单击core压缩包,在跳出的窗口里黏贴路径,点击解压(Extract)。
12、解压完成后,再次打开桌面上的Fakeapp,就正常进入软件了。
Fakeapp使用教程
该软件的使用主要分成了三个步骤, 使用之前请确保你的电脑配置还可以,推荐配置是:一张显存大于4G的N卡。该软件是有支持CPU选项,但是用CPU跑非常慢。获取脸部图片、训练模型、生成视频
在开始之前你需要先准备两个视频,一个是A视频,一个是B视频,换脸软件可以把B的脸换到A上面。这里加上A视频是FBB(范冰冰),B视频是FTM。这两个视频放在一个叫workspace的目录里面。下面的路径都为相对G:\FakeApp\workspace\的路径,路径并没有特殊要求,你可以更具自己的情况来选择。
一、获取脸部图片
1、选中GET DATESET 出现如下界面。
2、这一步的目的是讲视频分割成图片,然后从图片中提取脸部。
这个环节只需要填写两个地方,一个是Vidoe视频路径,一个是帧率FPS,默认为30.
3、因为我们有两个视频,所以需要分两次次来。.
先在Video中输入G:\FakeApp\workspace\FBB.mp4 ,这个路径不一定是这个样子要更具你的实际情况来。 帧率可以通过视频文件右键属性进行查看,一般是30,24之类。
输入完成后点击EXTRACT(提取) 开始提取。
4、提取分两个阶段,一个是把视频分割成图片,如上图。 一个是把图片中的人脸提取出来保存成新的图片,如下图。
5、等待进度条结束后跳出Traning dataset successfully 这个提示窗口就证明成功了。点击OK关闭提示窗口。
6、用同样的方式操作FTM.mp4
Video中输入G:\FakeApp\workspace\FTM.mp4 ,这个路径不一定是这个样子要更具你的实际情况来。同样需要输入帧率。
这两个过程完全是一样的,截图如下,就不多解释了。
二、训练模型
1、模型是很重要的一个东西,也是一个极其消耗时间的东西。训练模型对配置的要求也是比较高。
训练界面主要是上个输入框
Model : 模型的保存路径 (….\workspace\Model)
Data A: 被换的人脸(….\workspace\dataset_FBB\extracted)
Date B: 拿去换的人脸(…..workspace\dataset_FTM\extracted)
“….”代表你自己的路径。
2、输入路径之后,点击TRAIN开始训练。稍等片刻下面就会显示Loss A:xxxx ,LossB:xxxx 。 同时Model 目录下除了四个文件。同时还会跳出一个有很多脸的预览窗口。
3、这一个环节是非常耗时间的,一般需要几天时间。软件不会自动停止,你不想训练模型的时候可以手动关闭。下次开启会继续训练。 手动关闭的方法为,鼠标移动到预览窗口,然后按Q结束。
判断这个阶段是否完成了,可以通过两个指标去看。
①Loss A,Loss B 数字越来越像,小到了0.02左右,就差不多了
②人脸预览图越来越清晰,第二列第三列和第一列一样清晰,就证明差不多了。
训练结束后,即可开始生成视频。
4、生成视频的过程也是细分了好几个步骤。
首先,你需要输入Model 路径(…\workspace\Model )。Video路径(…\workspace\FTM.mp4) FPS(30)
然后,点击Create。
然后程序自动开始,处理过程可分成4个阶段。
①、生成图片
②、截取脸部
③、合成图片
④、合成视频
5、上面四个步骤是软件自动运行,运行结束之后就可以看到一个叫swap-FTM的视频了。这就是换脸后的视频。
因为我训练时间非常短,所以这个脸是非常模糊的,几乎看不起是谁。如果你训练的时间够长,这里就会非常清晰了。
软件功能
1、Processor:GPU/CPU这个选项用来指定运行环境,是选着GPU还是CPU。 一般来说如果你有显卡肯定选GPU,如果没有就选CPU,GPU的速度比CPU快几十倍的样子。
2、Batch Size:批量大小
这是一个深度学习中的专有名词,在训练的模型的时候并不是一次训练所有图片,而是分批进行训练。原则上来说越大越好(2的指数),但是数字越大消耗的显存越到,需要的配置越高。
3、Save Period: 保存间隔
默认为100,你可以根据自己的需要修改。
4、Nodes: 神经节点数
一般不修改,越大能力越强,需要配置越高。 如果你的电脑配置较低,可以适当降低这个值,比如改为256
5、Layer: 神经网络层数
一般不修改,越大能力越强,需要配置越高。
6、Mem Growth:内存增长
从理解上来说是,内存是否自动增长。
7、Men Ratio: 使用内存量 0.1/0.2/0.3
控制使用显存的大小。默认为自动,如果调整可能会出错。
8、Driection: A to B 转换方向
一般默认,也可以修改成B to A ,意思就是把B变成A。
9、Blur Size : 模糊的大小
融合的时候边缘模糊参数,如果感觉边缘比较生硬,可以适当增大这个参数。
软件特色
1、GET DATASET:获取数据集,在这一步中,你的素材视频将被逐帧切割成图片,程序会自动识别并提取出图片中人物的面部数据。2、TRAIN:训练模型,根据第一步中生成的数据集,机器会自动地帮你训练模型,从而进行面部的替换。
3、CREATE:生成视频,这一步便是整个实验中最为神奇的地方,他能根据你训练出的模型,将给定视频素材中人物的面部进行替换,最后生成替换后的视频。
常见问题
如何把A视频的脸,替换进B视频 ?
1、收集A,B的脸
因为是视频,所以要用一些特殊的技巧,把一个视频,转换成一张张图片,比如10s的视频,可能会有上百张图片,然后在上百张图片里,找出带有人脸的,最终都截取成相同大小的,比如256*256的脸图片
2、训练模型,A->B
有了A的256*256脸,和B的256*256脸,通过一些特殊的技巧,能找到两张脸之间联系,图片数越多,联系也就越紧,找到关系后,保存成 模型。这个模型的作用就是,给一张A的脸,输入进模型,模型会给出B的脸
3、换脸
随便找一个A的视频,依旧是转换成一张张图片,依旧要找出带有人脸的图片。把这一张张图片,丢进第2步得到的模型,就能得出一张张替换成B脸的图片。最后把所有的图片,再合并成视频,换脸完成。
fakeapp配置要求
1、硬件配置建议作业系统及CPU: 64Bit位
内存: 8G或以上
显卡:(CUDA)NVIDIA整合技术官方文档
CUDA Toolkit 8.0或CUDA Toolkit 9.1
2、辅助软件
JAVA程序 下载GO!…
Redistributable for Visual Studio 2015 下载位置
FFmpeg 下载GO!…
Light Image Resizer
Avidemux
猜你喜欢








相关推荐
-

neromediahome2022中文破解版
-

nerovideo2022中文破解版
-

会声会影2021入门版破解版
-

audialsmovie2022破解版
-

cyberlinkcolordirector(视频调色软件)
-

adobepremiereelements(视频编辑软件)2022简体中文破解版
-

vegaspro19绿色免安装版
-

sonycatalystbrowse
-

magixmovieeditpro2022premium破解版
-

ediuspro10完美破解版
-

aegisub中文破解版
-

magixmoviestudio18中文破解版
-

videosolovideoconverterultimate10.2.8中文破解版
-

万兴喵影工厂vip破解版
-

thefoundrynukestudio
- 软件周排行
- 软件总排行
- 01
aegisub中文破解版2021-08-12
- 02
magixmoviestudio18中文破解版2021-09-11
- 03
- 04
万兴喵影工厂vip破解版2021-09-10
- 05
thefoundrynukestudio2021-09-09
- 06

lightroom2018破解版2021-09-10
- 07

会声会影2021全能优化大师最新绿色版2021-02-27
- 08

avidmediacomposer2021-09-09
- 09

剪映pro2021-09-09
- 10

getflvpro2021-01-31
- 11

aftereffects2021绿色版2021-09-09